Par exemple, le conditionnement pour un héroïnomane va se faire avec l’attirail d’injection, les amis avec lesquels il injecte du fait des effets euphorisant entre le produit et le contexte d’injection. Ainsi, lorsque le sujet sera confronté au contexte ou bien au matériel d’injection, il ressentira un besoin irrésistible de consommer appelé craving (Siegel, 1983; Carter and Tiffany, 1999). Ce sont des effets renforçant sur la volonté du sujet de consommer (Sutton, 1998).
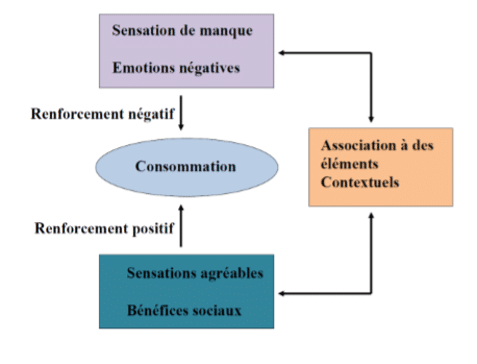
Sur le plan neurobiologique, ce conditionnement est sous-tendu par une sécrétion dopaminergique au niveau du système de récompense. Comprendre donc les mécanismes de ce conditionnement/apprentissage est un enjeu important pour la compréhension des mécanismes addictifs. Un des concepts clés pour expliquer l’apprentissage est l’erreur de prédiction. Le cerveau en se basant sur les expériences passées et le contexte de la situation actuelle effectue des prédictions des événements à venir en permanence. Les écarts entre la réalité et les attentes du cerveau vont être détectées. Plus les erreurs de prédiction sont grandes, meilleur sera l’apprentissage. Les neurosciences computationnelles calculent ces erreurs en utilisant la méthode de la différence temporelle (Sutton, 1988), qui va segmenter le temps en plusieurs fragments chacun contenant une prédiction de la valeur de la récompense à venir en fonction des expériences passées. Au niveau biologique, les erreurs de prédictions sont liées à des pulses transitoires de dopamine sécrétés par les neurones de l’aire tegmentale ventrale. Cependant les preuves que ces pulses transitoires soient réellement un signal d’erreur permettant l’apprentissage sont peu nombreuses.
Pour éclaircir ce point, une équipe de chercheurs canadiens (Maes et al., 2020) a combiné des techniques d’optogénétique permettant de contrôler (à la manière d’un interrupteur) ce pulse de dopamine avec des tâches d’apprentissage sur des rats.
Ils ont d’abord conditionné les rats qui ont régulièrement reçu des gouttelettes de glucose toujours précédées par l’apparition d’une lumière verte. Grâce à ce protocole, les rats ont appris à associer le fait de recevoir des gouttelettes de sucre avec l’apparition d’une lumière verte. Ainsi, en allumant la lumière, les rats vont se diriger vers la seringue qui sert à leur apporter la récompense et en mesurant le temps passé près de la seringue on peut quantifier la force de l’apprentissage de ces rats. Ils ont ensuite utilisé plusieurs tâches dans lesquels ils ont testés l’inhibition à différents moments entre l’indice (lumière verte) et la récompense (goutelettes de sucres) des neurones dopaminergiques de l’aire tegmentale ventrale. Ils ont montré que la sécrétion dopaminergique par les neurones dopaminergiques de l’ATV est indispensable pour l’apprentissage opérant. Par contre, ils n’ont pas pu déterminer si ce pulse de dopamine correspondait à une erreur de prédiction ou juste à la prédiction de l’arrivée d’une récompense. Pour répondre à cette question délicate, les auteurs ont utilisé un autre protocole d’apprentissage le “blocking”. Cette fois-ci, les auteurs présentent la lumière verte en premier, puis ils émettent un son et enfin délivrent des gouttelettes de sucre aux rats. La lumière verte annonçant déjà l’arrivée de la récompense (grâce au conditionnement précédent), le son n’est d’aucune utilité et ne va rien prédire. En effet, selon le paradigme de l’apprentissage par erreur de prédiction, l’apprentissage a lieu uniquement quand il y a des erreurs sur les prédictions à venir : il n’y a pas d’apprentissage sans surprise. Ainsi, s’il n’y pas d’association entre le son et la récompense et qu’on diffuse le son après avoir soumis les animaux au protocole de “blocking”, le rat ne va pas se déplacer vers la seringue.
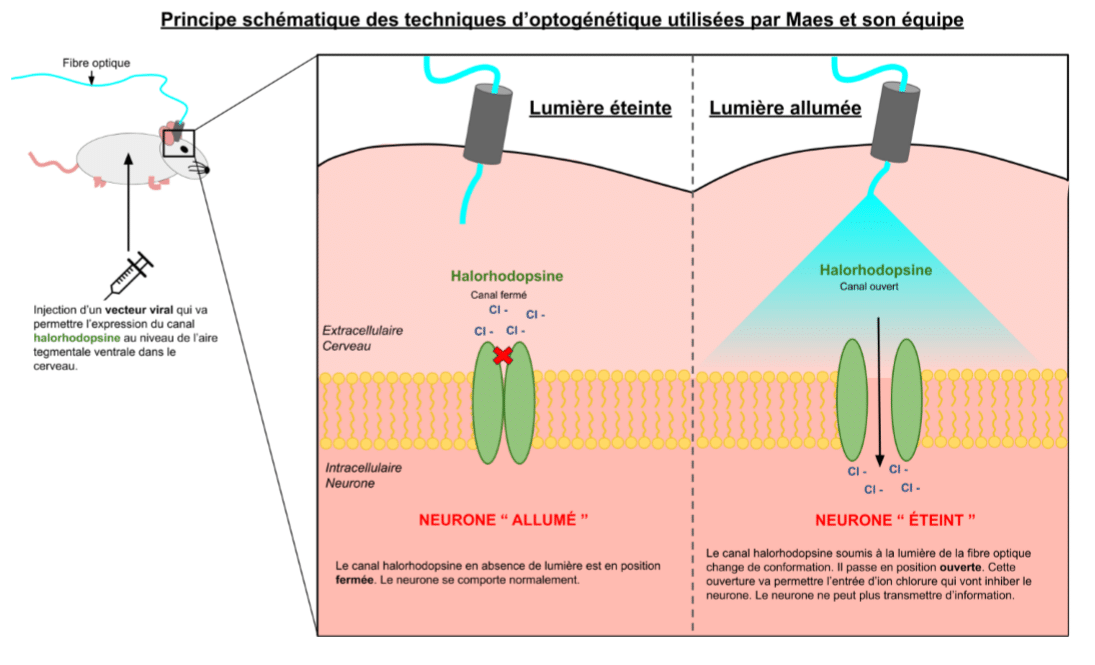
Les auteurs du papier (Maes et al., 2020) ont ainsi fait trois séries d’essais avec 3 sons différents pour pouvoir inhiber le potentiel pulse de dopamine à des moments différents et examiné si le pulse de dopamine est prédictif de l’erreur ou bien de la récompense. Ces séries d’expérience ont permis aux auteurs de valider que les pulses de dopamine dans l’aire tegmentale ventrale est indispensable pour un apprentissage conditionné mais également d’apporter des preuves solides que ce signal correspond bien à une erreur de prédiction. L’addiction est bien une pathologie du conditionnement à la récompense se traduisant par une anticipation permanente dans le temps de cette récompense immédiate. Il serait donc intéressant d’examiner comment le conditionnement est modifié chez des souris addicts. Comprendre et lier les mécanismes neurobiologiques aux observations des comportements est indispensable pour comprendre les processus sous-jacents de l’addiction. Les erreurs de prédiction temporelle pourraient notamment être en lien avec les difficultés à prendre des décisions adaptées dans la pathologie addictive.
Par Martin Leclercq et Laurence Lalanne-Tongio
Référence
Carter BL, Tiffany ST (1999) Meta-analysis of cue-reactivity in addiction research. Addiction 94:327– 340.
Maes EJP, Sharpe MJ, Usypchuk AA, Lozzi M, Chang CY, Gardner MPH, Schoenbaum G, Iordanova MD (2020) Causal evidence supporting the proposal that dopamine transients function as temporal difference prediction errors. Nat Neurosci 23:176–178.
Siegel S (1983) Classical Conditioning, Drug Tolerance, and Drug Dependence. In: Research Advances in Alcohol and Drug Problems: Volume 7 (Smart RG, Glaser FB, Israel Y, Kalant H, Popham RE, Schmidt W, eds), pp 207–246 Research Advances in Alcohol and Drug Problems. Boston, MA: Springer US.
Sutton RS (1988) Learning to predict by the methods of temporal differences. Mach Learn 3:9–44.
Sutton R and Barto A. Reinforcement Learning, MIT Press, 1998
